
Durante los últimos meses, los precios de la memoria RAM han subido sin freno, y muchos usuarios se preguntan por qué escasea un componente tan común.
Detrás de este fenómeno hay una pieza tecnológica poco conocida para el gran público, pero absolutamente clave en la nueva era de la inteligencia artificial: la memoria HBM (High Bandwidth Memory).
Su auge en la actualidad, está provocando un efecto dominó en toda la industria de los semiconductores.
¿Qué es la memoria HBM y por qué es tan importante en la actualidad?
La memoria HBM, siglas de High Bandwidth Memory, es un tipo de memoria ultrarrápida que se utiliza principalmente en tarjetas gráficas y aceleradores de IA. A diferencia de la RAM tradicional (DDR o LPDDR), la HBM se apila en capas verticales sobre el chip y ofrece un ancho de banda enorme con un consumo muy bajo.
En otras palabras, permite que las GPUs de inteligencia artificial y los procesadores de alto rendimiento trabajen con cantidades masivas de datos a velocidades imposibles para una RAM convencional. Fabricantes como NVIDIA, AMD o Intel la utilizan en sus componentes más potentes.
Mira y comprende el siguiente y muy aconsejable vídeo de "Hardware 360"..
La memoria HBM es una arquitectura DRAM 3D apilada con un bus extremadamente ancho y muy baja latencia efectiva, diseñada para alimentar con datos a GPUs y aceleradores de IA a ritmos que la DDR o GDDR no pueden alcanzar. Por eso se ha convertido en un pilar crítico los en servidores de IA modernos, donde el cuello de botella casi nunca es el cómputo bruto, sino la velocidad a la que se pueden mover terabytes de parámetros y activaciones.
La arquitectura de las memorias HBM física y lógica
La clave de HBM es el apilado vertical de matrices DRAM (dies) conectadas mediante TSV (Through-Silicon Vias), formando un “stack” de memoria de varias alturas. Cada pila se monta sobre un interposer de silicio que también aloja la GPU o ASIC, lo que reduce al mínimo la distancia física entre lógica y memoria.
- Cada stack agrupa múltiples matrices DRAM (hasta 8 en HBM2/2e y más en HBM3/HBM3e), creando un circuito integrado 3D.
- Las matrices se interconectan con TSV y microbumps, proporcionando miles de líneas de datos en paralelo.
- El interposer actúa como una “autopista” de muy alta densidad que une GPU/ASIC e HBM con buses masivos y muy cortos.
Lógicamente, cada stack se divide en múltiples canales de memoria independientes (por ejemplo, 8 canales de 128 bits), que en conjunto ofrecen una interfaz de 1024 bits por stack. Cada canal se comporta de forma similar a un canal DDR clásico, con sus bancos, filas y columnas, pero multiplicado en paralelo a lo ancho.
¿Cómo consigue tanto ancho de banda la HBM?
HBM no gana por frecuencia extrema, sino por “bus bruto”: muchos bits en paralelo a una velocidad moderada. Esto contrasta con GDDR, que usa buses más estrechos a frecuencias muy altas.
- Un solo stack HBM típico ofrece un bus de 1024 bits y puede alcanzar en primeras generaciones alrededor de 128 GB/s, subiendo a varios cientos de GB/s en HBM2/2e y superando los 800 GB/s por stack en HBM3.
- Una GPU con varios stacks puede superar holgadamente el terabyte por segundo de ancho de banda agregado.
Como las pistas físicas son cortas y el voltaje es reducido, la energía por bit transferido es muy inferior a la de GDDR o DDR, lo que permite mantener flujos de datos masivos dentro de un sobre térmico razonable.

Organización interna y acceso
A nivel interno, la DRAM de HBM sigue principios similares a DDR: bancos, filas, columnas y operaciones de activación y precarga. La diferencia está en cómo se orquesta el paralelismo:
- Cada canal HBM expone un bus de 128 bits operando en doble tasa de datos (DDR), sumando 1024 bits por stack.
- El controlador distribuye las solicitudes de lectura y escritura entre canales y bancos para maximizar la concurrencia y ocultar latencias.
- Al tener muchos canales, es posible mantener múltiples accesos pendientes (outstanding), alimentando los pipelines de cómputo sin interrupciones.
Desde el punto de vista del programador, HBM suele mapearse como un espacio de memoria lineal; la complejidad de reparto entre stacks y canales la gestiona el controlador de memoria del acelerador. Para cargas de IA que leen y escriben grandes tensores de forma secuencial o semisecuencial, este esquema es extremadamente eficiente.
Ventajas clave frente a DDR/GDDR en IA
HBM aporta tres ventajas técnicas fundamentales para workloads de IA a gran escala:
1. Ancho de banda masivo por chip
- Los modelos de IA de última generación manejan cientos de miles de millones de parámetros y activaciones intermedias que deben residir en memoria de alta velocidad.
- La relación FLOPs/GB/s de una GPU moderna está tan desequilibrada que, sin HBM, el cómputo quedaría ocioso esperando datos.
2. Eficiencia energética por bit
- El entrenamiento de grandes modelos consume enormes cantidades de energía en un datacenter; reducir la energía por acceso a memoria es crítico para el coste total de propiedad (TCO).
- HBM reduce consumo al necesitar menos chips externos, buses más cortos y menor voltaje, manteniendo un ancho de banda superior.
3. Factor de forma y densidad
- Al apilar memoria y colocarla en el mismo encapsulado, se libera espacio en la PCB y se simplifica el diseño de rutas eléctricas.
- Esto permite integrar decenas de gigabytes de memoria de alta velocidad justo al lado de la matriz de cómputo, algo inviable con GDDR a gran escala.
En conjunto, HBM hace posible que el throughput de datos se acerque al throughput de cálculo de las GPU o ASIC de IA, reduciendo el conocido “memory wall”.
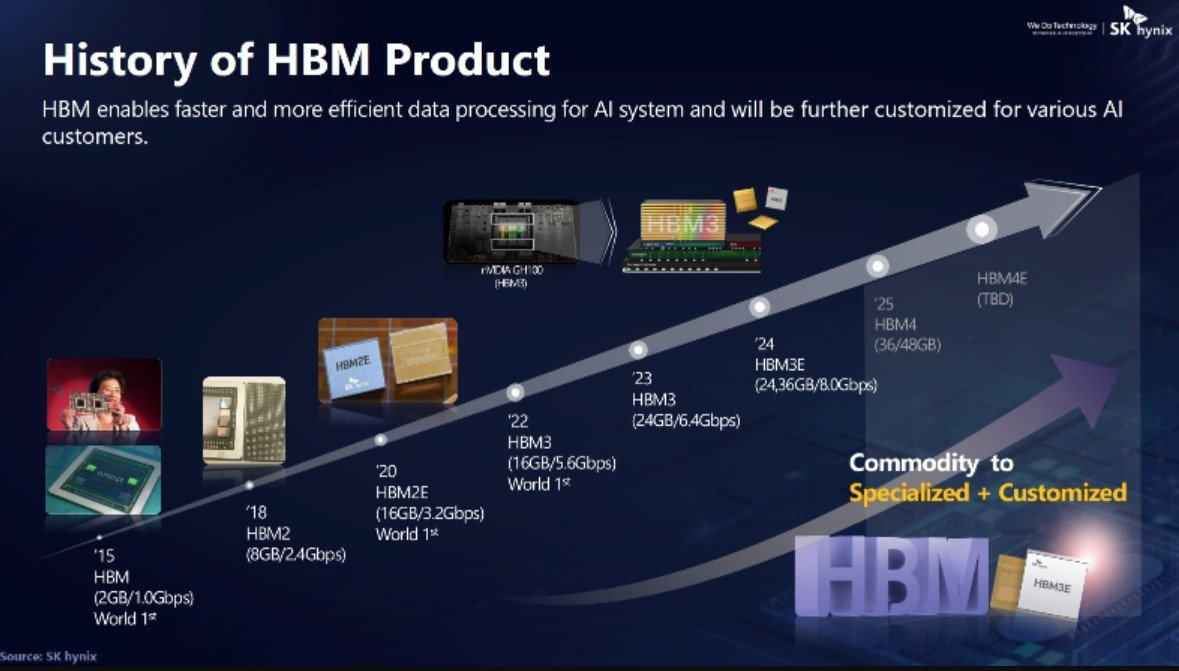
Existen varias generaciones de memoria HBM, cada una con especificaciones muy distintas en ancho de banda, capacidad por pila y velocidad de señal, pero todas comparten la misma base: DRAM apilada en 3D con un bus ultraancho de 1024 bits por stack. A continuación tienes un desglose técnico, planteado desde la perspectiva de arquitectura de hardware.
¿Qué generaciones de HBM existen?
La HBM (1ª generación) utiliza un bus por stack de 1024 bits, con una velocidad típica de alrededor de 1 Gb/s por pin, ofreciendo aproximadamente 128 GB/s de ancho de banda por stack. Su capacidad típica alcanza hasta 4 GB y emplea configuraciones de 4-Hi en la altura del stack.
La HBM2 mantiene un bus de 1024 bits, pero aumenta la velocidad hasta 2 Gb/s por pin, logrando aproximadamente 256 GB/s de ancho de banda por stack. Su capacidad puede llegar hasta 8 GB y utiliza configuraciones de hasta 8-Hi.
La HBM2e también emplea un bus de 1024 bits, pero eleva la velocidad hasta 3,2–3,6 Gb/s por pin, alcanzando entre aproximadamente 307 y 460 GB/s de ancho de banda por stack. Su capacidad puede llegar hasta 24 GB y admite alturas de hasta 12-Hi.
La HBM3 conserva el bus de 1024 bits (con mejoras en señalización y organización interna), incrementando la velocidad hasta aproximadamente 6,4 Gb/s por pin. Esto permite un ancho de banda de alrededor de 819 GB/s o superior por stack. Su capacidad típica es de 16 GB (con variantes que permiten más) y puede configurarse en alturas de 8 a 16-Hi.
Por último, la HBM4 (en proceso de estandarización) apunta a un bus superior a 1024 bits, con más canales y mayor densidad. Su velocidad será superior a la de HBM3, con un objetivo de más de 1 TB/s de ancho de banda por stack. Se espera que ofrezca capacidades de decenas de GB por stack y configuraciones de 16-Hi o superiores.
HBM (primera generación)
La HBM original nace para atacar el “memory wall” de GPUs frente a GDDR5, apostando por un bus extremadamente ancho en lugar de aumentar agresivamente la frecuencia.
- Interfaz lógica: 8 canales independientes de 128 bits cada uno, sumando 1024 bits por stack.
- Organización física: stacks típicamente de 4 matrices DRAM (4-Hi) sobre una base die, interconectadas mediante TSV y microbumps.
- Velocidad: alrededor de 1 Gb/s por pin, lo que proporciona unos 128 GB/s por stack.
- Capacidad: hasta 1 GB por die, 4 GB por stack y configuraciones de hasta 16 GB combinando cuatro stacks.
Desde la perspectiva del controlador, cada stack HBM se presenta como un conjunto de canales altamente paralelos, ideal para cargas con gran demanda de ancho de banda sostenido.
HBM2: salto en capacidad y rendimiento
HBM2 consolida la arquitectura y aumenta tanto rendimiento como densidad.
- Canales y bus: se mantiene el bus de 1024 bits por stack, organizado en 8 canales de 128 bits.
- Velocidad por pin: hasta 2 Gb/s (o algo más en implementaciones optimizadas), elevando el ancho de banda a unos 256 GB/s por stack.
- Capacidad por stack: hasta 8 GB oficialmente, usando configuraciones 8-Hi.
- Capacidad total en sistema: con varios stacks en el mismo paquete, se pueden alcanzar 32, 64 GB o más de memoria HBM2 integrada junto al die de cómputo.
Esto permite GPUs y aceleradores de IA con decenas de gigabytes de memoria de alta velocidad directamente integrados en el encapsulado.
HBM2e: extensión orientada a IA y HPC
HBM2e es una evolución incremental de HBM2, optimizada para cargas de IA y supercomputación.
- Mayor velocidad: entre ~3,2 y 3,6 Gb/s por pin, logrando más de 300 GB/s por stack en configuraciones estándar y cifras mayores en variantes optimizadas.
- Más altura de stack: soporte hasta 12-Hi, permitiendo capacidades de hasta 24 GB por stack.
- Uso típico: FPGAs de gama alta, SoCs adaptativos y aceleradores de IA que buscan un equilibrio entre coste, capacidad y ancho de banda.
En servidores de IA de generaciones anteriores a HBM3, HBM2e ha sido una solución muy extendida gracias a su buen balance entre rendimiento y madurez tecnológica.
HBM3: orientada a aceleradores de IA de frontera
HBM3 eleva significativamente el techo de rendimiento para GPUs y ASICs de última generación.
- Interfaz y organización: mantiene el concepto de 1024 bits por stack, con mejoras en granularidad de canales y señalización interna.
- Velocidad por pin: hasta ~6,4 Gb/s, permitiendo alrededor de 819 GB/s de ancho de banda por stack en especificación.
- Implementaciones reales: múltiples stacks pueden combinarse para superar los 2–5 TB/s de ancho de banda agregado en aceleradores de gama alta.
- Capacidad: pilas típicas de 16 GB, con variantes que incrementan densidad mediante stacks de mayor altura y técnicas avanzadas de empaquetado 2,5D/3D.
Con HBM3, el equilibrio entre capacidad de cómputo y ancho de banda vuelve a alinearse, evitando que las unidades de cálculo queden infrautilizadas por falta de datos.
HBM4: próxima generación (en definición)
HBM4 es la evolución prevista para soportar modelos de IA aún más grandes y cargas de trabajo de datos masivos.
Las líneas de diseño apuntan a:
- Mayor densidad: más capas (16-Hi y superiores) y mayor densidad por die, con decenas de GB por stack.
- Más ancho de banda: objetivo de superar 1 TB/s por stack, aumentando velocidad por pin y/o número efectivo de canales.
- Mejor eficiencia energética: reducción adicional de energía por bit transferido, clave en datacenters limitados por potencia y refrigeración.
- Integración avanzada: uso más intensivo de empaquetado 2,5D/3D, interposers activos y tecnologías de puente de silicio para mejorar integridad de señal y reducir latencia.
HBM4 se perfila como un componente estratégico en la próxima generación de plataformas de IA a gran escala.
¿Cuáles son sus usos más habituales?
Desde la perspectiva de arquitectura de sistemas:
- HBM / HBM2: adecuadas cuando priman coste, madurez tecnológica y necesidades de ancho de banda moderadas.
- HBM2e: punto de equilibrio para soluciones de IA y HPC que requieren alto ancho de banda sin la complejidad total de HBM3.
- HBM3: elección natural para aceleradores de IA de frontera, donde cada incremento de ancho de banda reduce tiempos de entrenamiento y coste por modelo.
- HBM4: objetivo para futuras generaciones de GPU/ASIC orientadas a modelos multimodales gigantes y análisis masivo de datos.
Cada salto generacional en HBM no solo incrementa velocidad y capacidad: redefine el límite práctico de rendimiento de toda la plataforma, impactando la red de interconexión, la jerarquía de memoria secundaria y la economía global del datacenter.
¿Por qué es tan crítica la HBM para los servidores de IA?
En un servidor de IA típico (por ejemplo, un nodo con varias GPUs con HBM), el rendimiento de entrenamiento o inferencia a gran escala está limitado por la jerarquía de memoria tanto dentro del nodo como entre nodos.
HBM ocupa el escalón de memoria “caliente” más importante.
- Entrenamiento de LLMs: los pesos del modelo residen en HBM para minimizar la latencia y maximizar el throughput de las operaciones de matriz.
- Inferencia de baja latencia: respuestas en tiempo casi real exigen que las rutas críticas de datos vivan en HBM, evitando accesos más lentos a la memoria del host.
- Escalado multi-GPU: cuanto más rápido puede cada GPU consumir datos locales, antes puede sincronizar gradientes con otras GPUs, reduciendo el tiempo por iteración.
Si se sustituyera HBM por DDR5 o incluso GDDR6, el ancho de banda agregado por GPU caería drásticamente, incrementando el tiempo de entrenamiento, el coste por token y el consumo energético global.
Desde la perspectiva de un proveedor de nube o un laboratorio de IA, esto comprometería la viabilidad económica de entrenar y servir modelos de frontera.
¿Cómo la HBM provocó la crisis de la memoria RAM en 2026?
El auge de la inteligencia artificial generativa y el entrenamiento de modelos como ChatGPT o Gemini ha disparado la demanda de chips con memoria HBM.
Este tipo de memoria no se fabrica por separado: usa las mismas líneas de producción base que la DRAM tradicional, la misma “materia prima” necesaria para crear módulos de memoria RAM.
El resultado directo es un cuello de botella:
- Los grandes fabricantes (Samsung, SK Hynix, Micron) han desviado gran parte de su capacidad de producción a la HBM.
- La RAM convencional, usada en PCs, portátiles y servidores comunes, ha pasado a un segundo plano.
- Menos oferta y más demanda = precios disparados y escasez para los consumidores domésticos.
Según analistas del sector, la producción global de HBM aumentó más de un 200% en 2025, mientras que la fabricación de DRAM estándar apenas creció un 5%.
Impacto en los precios y en el mercado
A finales de 2025, el precio de los módulos DDR5 subió entre un 30% y un 40%, afectando tanto a usuarios particulares como a fabricantes de equipos y centros de datos.
Este encarecimiento también afecta indirectamente a dispositivos móviles, consolas y equipos de gaming.
De hecho, muchos expertos comparan el fenómeno con la “crisis de los chips” de 2021, cuando la escasez global disparó los precios de componentes básicos. La diferencia es que ahora el motor del cambio es la inteligencia artificial.
HBM vs RAM tradicional: principales diferencias
| Característica | HBM (High Bandwidth Memory) | DDR / LPDDR (Memoria RAM) |
|---|---|---|
| Velocidad | Muy alta (hasta 1 TB/s) | Moderada |
| Consumo energético | Bajo | Medio/alto |
| Aplicaciones | IA, GPU, supercomputación | PCs, portátiles, móviles |
| Coste de producción | Muy alto | Relativamente bajo |
| Disponibilidad | Limitada | Global, pero reducida por la crisis |
¿Qué pasará en 2026?
Todo apunta a que la situación seguirá tensionada durante gran parte de 2026. Mientras la IA siga siendo el gran motor de inversión tecnológica, los fabricantes priorizarán la producción de HBM frente a la DRAM tradicional.
Algunos expertos estiman que los precios de la RAM podrían estabilizarse a mediados de 2027, cuando nuevos fabricantes (como Nanya o CXMT) logren expandir su capacidad.
Además, se espera la aparición de nuevas generaciones como HBM4 y DDR6, que podrían equilibrar el mercado al diversificar la oferta.
Conclusión
La memoria HBM es el “cerebro rápido” que permite a la inteligencia artificial funcionar a gran escala, pero su éxito está teniendo consecuencias inesperadas para los usuarios comunes.
La memoria HBM no es solo “RAM más rápida”: es una pieza estructural del diseño de servidores de IA modernos porque alinea tres vectores críticos al mismo tiempo: ancho de banda extremo, eficiencia energética y densidad próxima al cómputo. Sin este equilibrio, la actual generación de modelos de IA no sería practicable a las escalas que conocemos.
La crisis de la memoria RAM no es solo un problema de escasez, sino un síntoma de cómo la tecnología avanza más rápido de lo que la industria puede producir.
En resumen, la revolución de la IA también tiene coste en gigabytes y euros; y aunque, la HBM impulse la innovación, los consumidores tendrán que pagar el precio (literalmente) de ese grandísimo salto tecnológico.